Google представили Titan: архитектуру нейросетей, которая может стать новой серебряной пулей LLM
Все современные LLM построены на архитектуре трансформера. GPT-4o от OpenAI, Gemini от Google, Claude Sonet от Anthropic, Grok от xAI… перечислять можно долго. Трансформер – действительно очень мощная архитектура (и кстати тоже была придумала в Google), но и в ней есть свои недостатки.
В частности, трансформеры очень прожорливы и забывчивы: чем больше последовательности, которые они обрабатывают, тем больше ресурсов для этого требуется, и тем больше ошибок они допускают. Это одна из основных проблем сегодняшнего ИИ, потому что такое поведение сильно ограничивает способность модели работать, например, с большой базой данных, или с большим кодовым проектом, или с последовательностями геномов.
В своей новой статье Google предложили элегантное решение: их Titan легко масштабируется на последовательности 2+ млн токенов, при этом не теряя в точности (трансформеры обычно начинают проседать уже после отметки 4096, то есть в 500 раз меньше). Сейчас разберемся, как ученым это удалось.
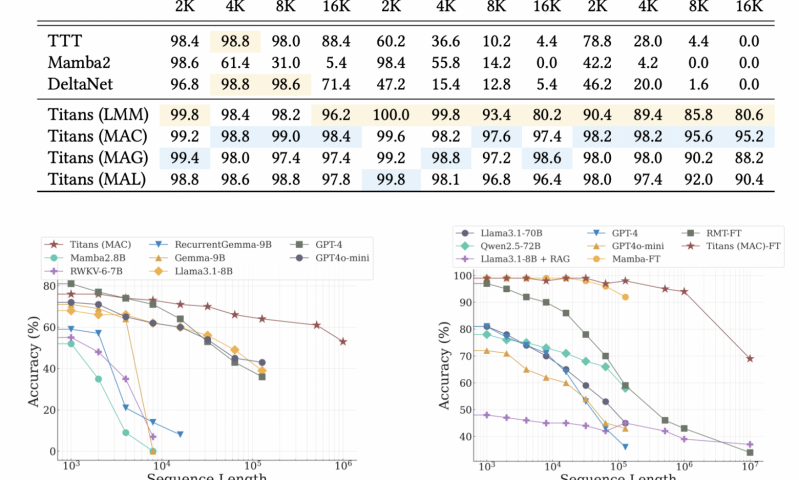
На графиках хорошо видно, насколько более стабильно ведет себя Titan с ростом последовательности относительно других моделей: красная прямая убывает плавно и находится выше остальных
В основе трансформера лежит механизм внимания. Суть механизма заключается в том, что мы “взвешиваем” релевантность всех токенов последовательности относительно друг друга: каждый с каждым. На практике это реализуется как перемножение трех тензоров: Query, Key и Value. Воспринимать Query, Key и Value можно как составляющие, необходимые для “умного поиска” по последовательности: запросы, ключи и значения. При их последовательном перемножении мы и получаем тот самый attention, который показывает значимость связей между словами. Именно основываясь на этих связях модель может глобально понимать тексты, которые читает, а затем один за одним предсказывать следующие токены, из которых получаются осмысленные ответы на ваш запрос.
Лирическое отступление: если вы хотите поближе познакомиться с трансформером и понять, почему именно он стал серебряной пулей нейросетей, прочитайте нашу статью “Что, если не трансформеры”.
А если хотите каждый день читать что-нибудь интересное про ML, то приглашаем вас в наш тг-канал Data Secrets. Там мы (а мы – это команда действующих ML-инженеров) каждый день наблюдаем за повесткой, публикуем разборы свежих статей и релизов и делимся прикладными материалами. А еще наше большое сообщество всегда радо новым специалистам и энтузиастам 🙂
Но вернемся к вниманию. Как вы поняли оно – основная действующая сила трансформера. Но, как это часто бывает, оно же – его главная слабость. Дело в том, что из-за того что каждый токен надо взвешивать относительно каждого, архитектура масштабируется квадратично по мере увеличения длины последовательности.
То есть, когда длина последовательности, обрабатываемой трансформером (скажем, количество слов в отрывке), увеличивается на заданную величину, требуемые для обработки вычисления увеличиваются на эту величину в квадрате и быстро становятся неподъемно огромными. Это приводит к проблеме невозможности увеличения контекстного окна и той самой проблеме забывания.
В Google предложили немного иной подход к “памяти” модели. Помимо краткосрочной памяти, в основе которой остался attention и которая хорошо работает на коротких последовательностях, исследователи добавили в архитектуру долгосрочную память и постоянную память.
Другими словами, у нас есть некоторый core – стандартное внимание с ограниченным окном, которое применяется, например, к последнему сообщению в диалоге; – и модуль, который хранит важную информацию из “далекого прошлого”. Эта важная информация может быть постоянной (модуль постоянной памяти) или обновляться прямо во время инференса (модуль долгосрочной памяти).
Во время обновления модель с помощью специальной метрики “сюрприза” оценивает, какие токены удивили ее больше всего: логика тут в том, что чем “неожиданнее” новые данные для модели, тем важнее их запомнить. Кроме того, в долгосрочной памяти присутствует коэффициент затухания: если что-то не пригождается, можно постепенно это забывать. Еще одно важное замечание состоит в том, что такая долгосрочная память, сохраняет главное свойство трансформера, то есть может эффективно параллелиться.
Три перечисленных модуля памяти (постоянная, краткосрочная, долгосрочная) исследователи пробовали соединять тремя разными способами:
-
Memory as Context: долгосрочная память используется как контекст для текущего внимания. То есть вместо того, чтобы смотреть на весь огромный контекст, окно внимания смотрит на последние его части + ту выборочную информацию, которую хранит долгосрочная память.
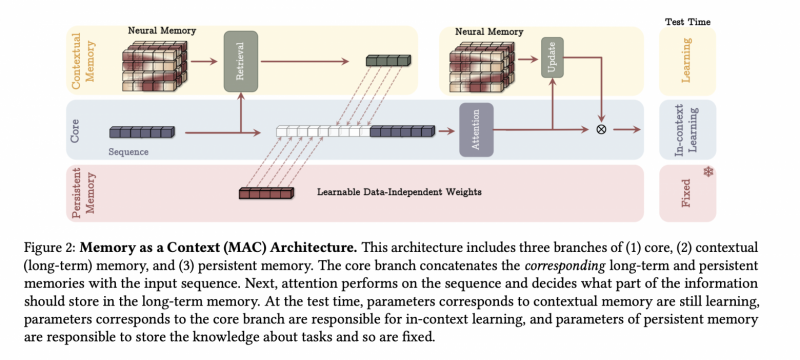
-
Memory as Gating: этот вид очень похож на LSTM с ее механизмом гейтов. Разные виды памяти как бы текут по разным каналам, проходят внутри одного слоя через разные активации и сливаются с определенными весами.
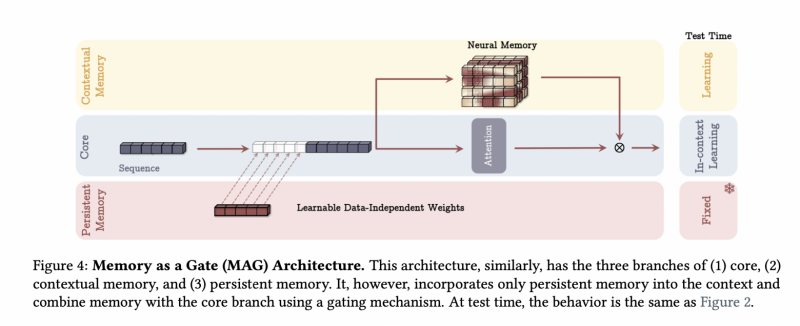
-
Memory as Layer: самый простой вариант последовательного соединения. Входные токены проходят через модули памяти слой за слоем.
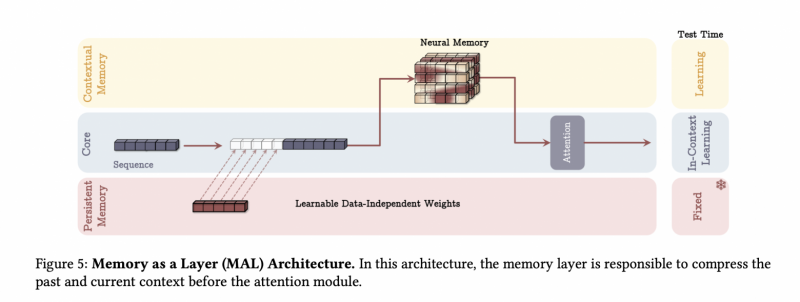
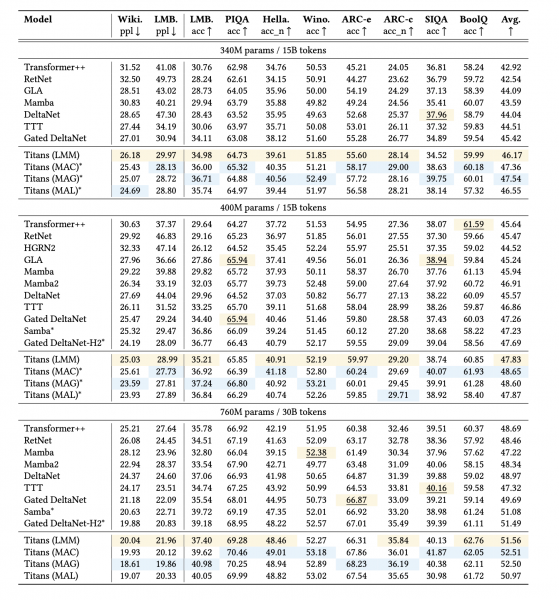
Лучше всего по метрикам показал себя первый вариант – MAC, а самым быстрым оказался MAL. В целом такая архитектура может легким движением руки масштабироваться до контекста в 2+ миллиона токенов, сохраняя стабильную точность (напоминаем, трансформеры начинают фейлить уже после отметки 4096). В таблицах метрик хорошо видно, насколько лучше Titan справляется с теми задачами, для которых важно обрабатывать большие входные данные и помнить важную информацию из всего контекста. Помимо точности, в Titan обработка длинных последовательностей еще и более дешевая, то есть требует гораздо меньше операций.
Очень крутая работа получилась у Google, в общем. Пока непонятно, получится ли у Titan затмить трансформер, но шансы точно есть!
Полный текст статьи ищите здесь.