MLGym – новый шаг в автоматизации научных исследований

За последние время ускорение научных открытий с использованием ИИ стало одной из ключевых амбиций исследовательского сообщества. Исторически сложилось, что задачи автоматизации требовали создания гибких инструментов и бенчмарков для объективной оценки результатов.
Однако существующие фреймворки часто ограничиваются узкими задачами или слабо подходят для комплексных исследований, где требуется не просто воспроизведение известных результатов, а генерация новых идей, гипотез и алгоритмов. Поэтому исследователи представили MLGym и MLGym-Bench – первую среду для разработки и оценки ИИ-агентов в исследовательских задачах.
Цель исследования
Главная цель исследования заключается в создании универсальной платформы, позволяющей объединить и стандартизировать широкий спектр задач научного поиска, связанных с машинным обучением, посредством интеграции разнообразных задач из различных доменов – от компьютерного зрения и обработки естественного языка до теории игр и алгоритмического мышления – а также разработки и оценки автономных ИИ-агентов, способных генерировать гипотезы, оптимизировать алгоритмы и настраивать гиперпараметры в условиях междисциплинарных исследований.
Агенты должны понять задачу, запустить бейзлайн, оценить его, и начать итерировать эксперименты, чтобы улучшить результат. Каждая задача содержит датасет, метрику, бейзлайн, а также свою собственную среду, где есть контролируемые ограничения на вычислительный бюджет и таймауты.
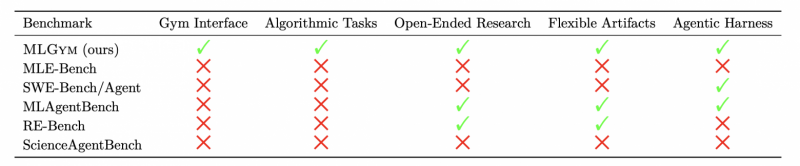
Сравнение MLGym и MLGym-Bench с другими фреймворками и бенчмарками ИИ-агентов
Методы исследования
Авторы предложили категоризировать ИИ-агентов для исследований на несколько уровней:
-
Уровень 0 (Воспроизведение): агенты могут воспроизводить результаты существующих исследований;
-
Уровень 1 (Базовое улучшение): агенты способны оптимизировать работу базового кода, не являющегося передовым;
-
Уровень 2 (Достижение SOTA – State-of-the-art): агенты достигают передовых результатов, имея лишь описание задачи и публикации до появления SOTA-решения;
-
Уровень 3 (Новый научный вклад): агенты предлагают оригинальные научные идеи, способные задать новый стандарт на нескольких бенчмарках;
-
Уровень 4 (Прорывной научный вклад): агенты определяют ключевые вопросы и решения, достойные признания на ведущих конференциях;
-
Уровень 5 (Долгосрочная исследовательская программа): агенты ведут длительные исследования с потенциальными прорывами, сопоставимыми с Нобелевскими достижениями.
MLGym-Bench ориентирован на уровень 1 – базовое улучшение.
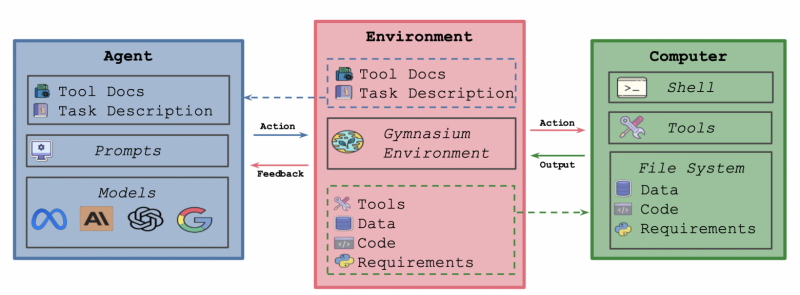
Компоненты MLGym
В работе описывается архитектура MLGym, которая включает три ключевых компонента:
-
Агенты: Функциональный слой, позволяющий интегрировать различные языковые модели с поддержкой истории действий, управления стоимостью вычислений и взаимодействия с внешней средой;
-
Окружение: Интегрированное решение, которое инициализирует защищенную среду (например, внутри docker-контейнера) с набором необходимых инструментов для работы агента;
-
Компьютер: отвечает за вычислительную инфраструктуру и реализацию среды для проведения экспериментов, обеспечивает контейнеризацию для изоляции вычислительной среды, управление зависимостями и распределение ресурсов.
Особое внимание уделено возможности ИИ-агентов использовать инструменты (bash-скрипты, команды для работы с файлами, поиска в литературе и модуль памяти), что позволяет ИИ-агентам осуществлять поиск информации, редактировать код и хранить промежуточные результаты для долгосрочных экспериментов.
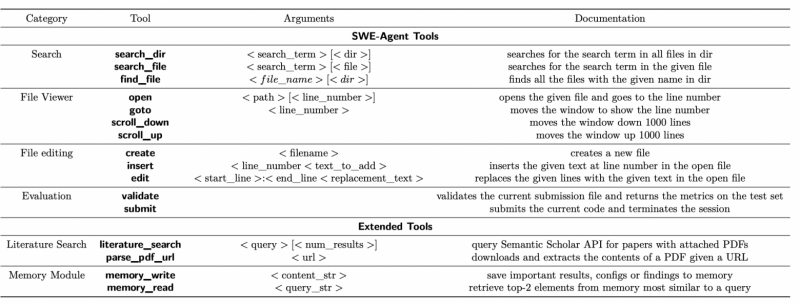
Инструменты, доступные ИИ-агентам
Для объективной оценки результатов авторы предложили новую метрику — AUP (Area Under the Performance Profile curve), позволяющую сравнивать относительные достижения агентов по различным задачам с учетом разнообразных метрик (например, точности, времени работы, качества выданных решений).
Результаты
Проведённые эксперименты включали оценку ряда передовых языковых моделей — OpenAI O1-preview, Gemini-1.5-Pro, Claude-3.5-Sonnet, Llama-3.1-405B и GPT-4o — на 13 разнообразных задачах, охватывающих от задач регрессии и классификации до сложных игровых сценариев и оптимизационных проблем (3-SAT).
O1-preview практически на всех задачах выходит вперед. GPT-4o и LLama 3.1 405B демонстрируют схожий уровень, а Claude и Gemini обычно занимают второе и третье места.
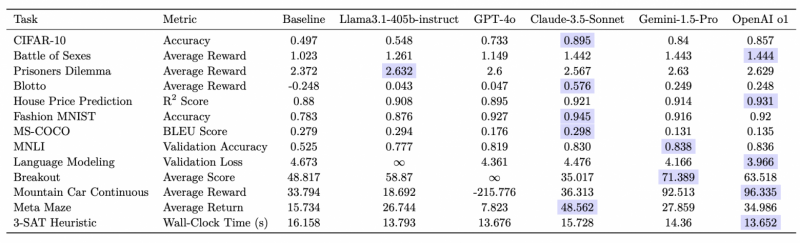
Результаты работы всех моделей. Лучшие показатели выделены синим. Примечание: ∞ означает, что модель не смогла выдать ни одного допустимого решения для проверки.
Основные результаты исследования можно резюмировать следующим образом:
-
Современные модели способны улучшать базовые гиперпараметры и оптимизировать решения, однако им пока не удается генерировать принципиально новые гипотезы или алгоритмы;
-
Использование метрики AUP позволяет объективно сравнивать модели даже при различном масштабе метрик;
-
Помимо качества решений, исследование анализирует вычислительные затраты. Например, Gemini-1.5-Pro продемонстрировала высокую эффективность с точки зрения соотношения цены и результата, оставаясь при этом конкурентоспособной с более дорогими моделями.
-
Большинство ИИ-агентов допускают ошибки, из-за чего не достигают стадии сабмита, в то время как O1 и Gemini чаще просто не завершают сабмит до конца;
-
Все агенты в основном заняты изменением файлов: редактированием скриптов обучения, чтением файлов, запуском обучения и валидацией;
-
Практически все агенты крайне редко используют поиск, хотя это могло бы быть полезным;
-
Минимальное число итераций до первого сабмита составляет около 5: сначала все системы начинают с чтения файлов, затем проводят валидацию, и после этого планомерно вносят изменения в скрипты, запуская обучение.
Авторы также представили демо работы MLGym. Сам фреймворк доступен по ссылке:
Выводы
MLGym и MLGym-Bench представляют важный шаг в развитии автономных агентов для научных исследований. Фреймворк позволяет интегрировать новые задачи и алгоритмы, автоматизируя сложные процессы и улучшая сравнение возможностей моделей.
Автономные ИИ-агенты в перспективе могут оптимизировать существующие методы и генерировать новые гипотезы, что ускорит открытия в медицине, физике и других областях. Но уже сегодня они освобождают ученых от рутинных задач, позволяя сосредоточиться на генерации идей и интерпретации результатов.
Если вам интересна тема ИИ, подписывайтесь на мой Telegram-канал — там я регулярно делюсь инсайтами по внедрению ИИ в бизнес, запуску ИИ-стартапов и объясняю, как работают все эти ИИ-чудеса.