
Разбираемся, как устроена R1 – новая бесплатная ризонинг модель ИИ из Китая, работающая на уровне o1 от OpenAI
Вчера, 20 января, китайская лаборатория DeepSeek сделала нам всем настоящий подарок, открыв доступ к новой reasoning-модели R1, которая уже штурмует вершины ML-бенчмарков.
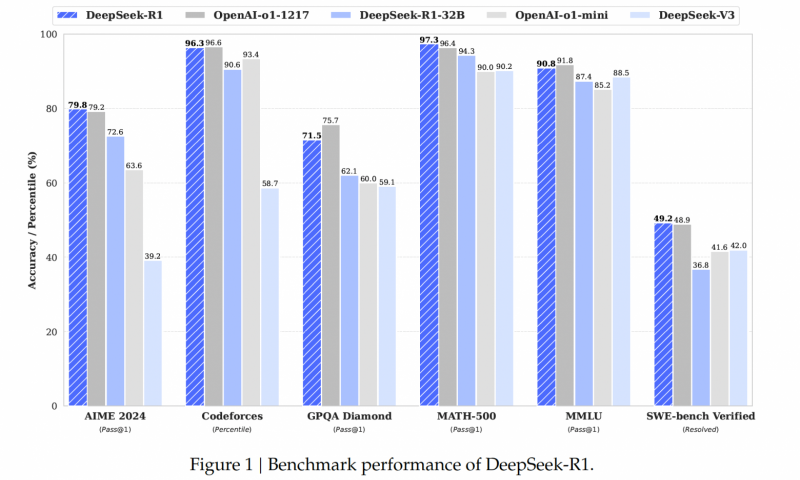
R1 – не просто еще одна рассуждающая модель: это первая бесплатная моделька с открытыми весами, которая добивается таких результатов. На математическом бенчмарке AIME 2024 она достигает 79.8%, обогнав даже обновленную версию o1 с ее 79.2%, не говоря уже об o1-mini (63.6%). В кодинге R1 тоже хороша. Например, на Codeforces ее результат – 96.3%, что практически недостижимо для большинства людей.
Моделью уже можно воспользоваться в чате chat.deepseek.com/. Доступно 50 сообщений в день, VPN не требуется. И самое прекрасное: кроме весов и кода DeepSeek выложили замечательный тех.отчет, в котором подробно описали, как им удалось обучить такую мощную модель. Сейчас мы разберем его по полочкам.
Итак, надо сказать, что на самом деле DeepSeek представили не одну модель, а целых 8: саму R1, ее младшую сестренку R1-Zero и 6 дистиллированных, то есть уменьшенных, моделей. К ним еще вернемся, о пока начнем с R1 Zero.
Несмотря на то, что R1 – умнейшая из них, самая интересная с точки зрения техники исполнения, пожалуй, именно R1-Zero. Ноль в названии фигурирует не просто так. Дело в том, что R1-Zero была обучена вообще без использование каких-либо размеченных людьми данных. Учитывая ее результаты, это просто поражает. Большинство LLM обучаются в три этапа:
-
Претрейн на большом количестве текста. На этом этапе модель выучивается понимать текст и связно его генерировать, а также запоминает факты и набирается общих знаний о мире и языке.
-
Файнтюнинг. Обучение на размеченных данных вида <вопрос-идеальный ответ>. Нужно для того, чтобы модель научилась лучше следовать инструкциям. Именно на этом этапе обычно наблюдается значительное улучшение метрик, потому что модель начинает не просто генерировать какой-то связный текст, а делать это именно так, чтобы хорошо выполнять поставленные задачи.
-
Обучение с подкреплением. Здесь модель дорабатывают, чтобы она лучше соответствовала пользовательским ожиданиям и была максимально полезной. Например, её учат более корректно и чётко формулировать ответы или избегать вредоносного или неуместного контента.
Теперь представьте, что R1-Zero пропустила второй этап с разметкой полностью. Это значит никакого файнтюнинга на размеченных данных “вопрос-ответ”, только базовая предобученная модель DeepSeek-V3-Base и Reinforcement Learning, который тоже реализован без использования разметки. В качестве алгоритма RL традиционно для DeepSeek применяется GRPO, улучшенная версия PPO. Отдельно поощряется формат, в котором модель помещает свои рассуждения внутри тегов <think> и </think>.
Лирическое отступление: если вы хотите лучше понять, как устроено обучение с подкреплением, для чего оно нужно, и как работают алгоритмы PPO и GRPO в частности, прочитайте нашу большую статью “DeepSeekMath или как научить LLM решать математические задачи”.
А если хотите каждый день читать что-нибудь интересное про ML, то приглашаем вас в наш тг-канал Data Secrets. Там мы (а мы – это команда действующих ML-инженеров) каждый день наблюдаем за повесткой, публикуем разборы свежих статей и релизов и делимся прикладными материалами. А еще наше большое сообщество всегда радо новым специалистам и энтузиастам 🙂
Вернемся к R1-Zero. Несмотря на то, что для нее полностью пропустили этап файнтюнинга, ее результаты поражают. Во-первых, после нескольких тысяч итераций RL точность на математическом тесте AIME скакнула с 15.6% в базовой модели до 71.0% (вау!), и уже здесь DeepSeek опередили o1-mini.
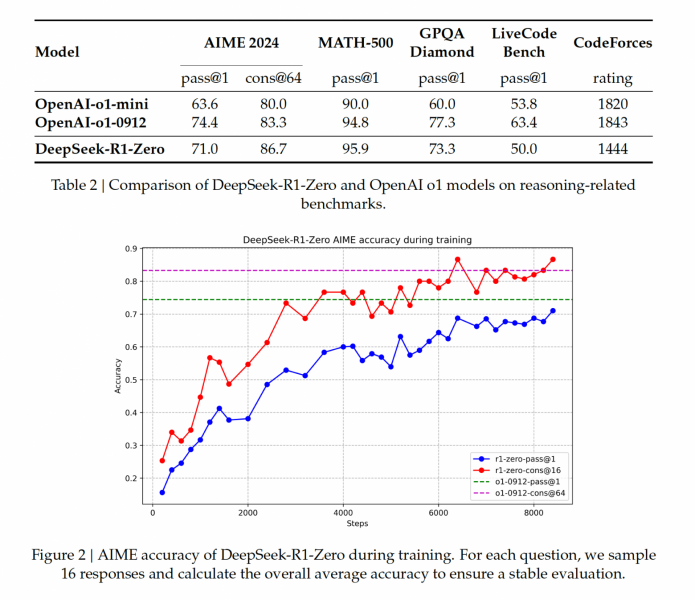
Во-вторых, посмотрите на график ниже. Он показывает, как росла длина ответом модели по мере тренировки. Получается, что R1-Zero по мере обучения буквально учиться рассуждать дольше и за счет этого получать лучшие результаты!
А еще модель даже самостоятельно научилась находить и выделять “ага-моменты”, то есть постигать какие-то ключевые инсайты, необходимые для решения, или, иными словами “догадываться” до чего-то только благодаря тому, что хорошо подумала. Вот такая вот сила обучения с подкреплением.

Напоминаем, что все это – вообще без разметки. Неплохо, да?
Однако DeepSeek пошли дальше, и для повышения качества решили все-таки добавить подготовленные вручную данные в процесс обучения. Так появилась R1. Для нее, в целом, пайплайн обучения и даже алгоритм RL остаются такими же, с небольшой разницей. Для R1-Zero в RL мы использовали rule-based rewards, когда ответы проверяются только самой системой, без внешних разметок. Например, если задача на программирование — в компиляторе проверяется успешное выполнение тестов на написанном коде.
И хотя точность таким образом получается приличная, сами ответы читать сложно: в них смешиваются языки, нет форматирования и тд. Поэтому R1 в начале дообучили на специально подготовленных готовых цепочках рассуждений. Данные брали из DeepSeek-R1-Zero и, видимо, o1, а затем отбирали + улучшали вручную.
Эти же данные затем также применяют в RL. А еще ключевую роль здесь сыграл подход rejection sampling: во время обучения модель генерировала множество вариантов ответов, из которых отбирались лучшие. Эти отборные ответы возвращались в обучающую выборку, чтобы постепенно повышать качество как самих рассуждений, так и итогового результата. Получился отлично функционирующий цикл вида “генерация → отбор → дообучение”.
Относительно R1-Zero метрики тут еще более впечатляющие, и уже тягаются с полноценной o1. Но есть интересный факт: когда на этапе RL для R1 ввели правило “доля таргетного языка в ответе должна быть больше 0.95”, качество немножко просело.
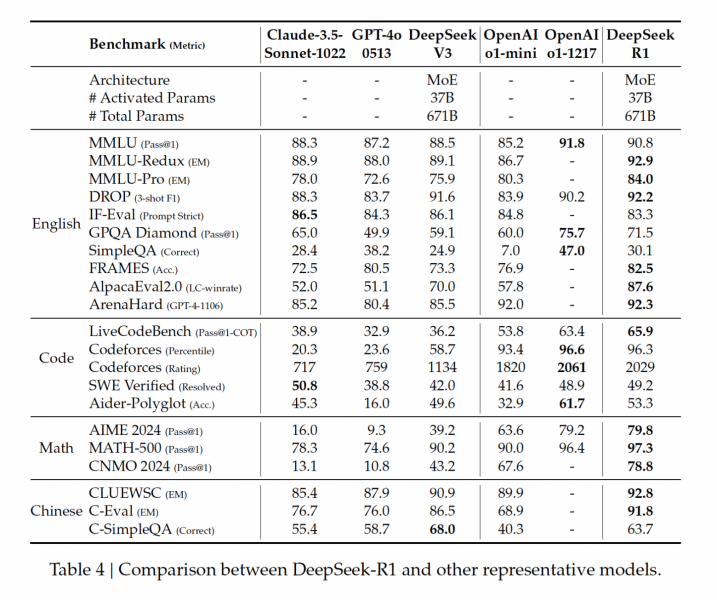
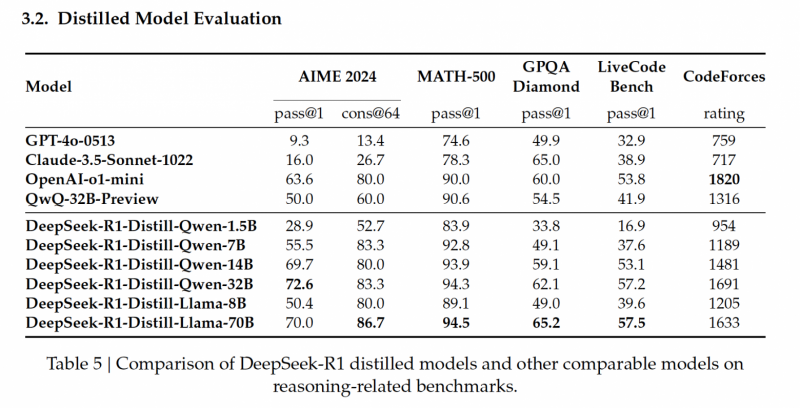
Наконец, дистиллированные модели. Они нужны, потому что сама по себе R1 огромная – 685B параметров. Это значит, что ее почти невозможно запустить локально, если вы не GPU-rich. А локальный запуск очень важен, особенно для исследователей или тех, кто хочет использовать R1 безлимитно или оффлайн на своей машине. Поэтому лаборатория DeepSeek позаботились о том, чтобы у нас были мини-версии ее ризонера.
Вообще, дистилляция – это когда мы переносим знания из большой сложной модели (учителя) в меньшую и более простую модель (ученика). Цель в том, чтобы создать модель пободрее и поменьше, но такую, которая сохраняет большую часть перформанса исходной. В данном случае в качестве учителя выступает R1, а в качестве учеников – открытые Qwen и Llama.
Процесс был примерно такой: из R1 насемплировали 800,000 примеров, на которых ванильно зафайнтюнили учеников. Тут, к слову, вообще не использовался RL, но в статье написано, что ученые хотят попробовать его применить.
В итоге кроме R1-Zero и R1 у нас есть целых 6 их падавана на 1.5B, 7B, 14B, 32B, 8B, 70B. При этом 32 и 70 на уровне o1-mini, а 1.5B аутперформит GPT-4o и Сlaude Sonnet!
В общем, очень крутая работа получилась у DeepSeek. Они не только еще раз показали нам силу RL, но и напомнили, что передовые модели ИИ не обязательно должны скрываться за семью печатями, а могут оставаться открытыми и доступными.
Полностью тех.отчет читайте здесь, пробуйте R1 здесь, а веса дистилляций качайте вот тут. Высоких вам метрик!

{kind=link}